操作系统
进程与线程
- 进程:一个在内存中运行的应用程序,每个进程都有自己独立的一块内存空间,一个进程可以有多个线程。
- 线程:进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。
- 区别
- 进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
- 每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换开销大;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
- 同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
- 一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。
谷歌浏览器为什么是多进程
浏览器存在单进程架构和多进程架构
单进程架构
- 所有的功能模块都是运行在同一个进程里的。可能会导致 不稳定、不流畅、不安全。
对进程架构
- 具备更好的容错性,提供安全性和沙盒性。
- 谷歌浏览器的进程:
- 浏览器进程(Browser Process),浏览器的主进程,负责包括地址栏、前进后退按钮、处理网络访问、文件访问等。
- 渲染进程(Renderer Process),控制显示网站的选项卡内的所有内容。
- 插件进程(Plugin Process),控制网站使用的所有插件。
- GPU(GPU Process),与其他进程隔离处理GPU任务,由于GPU处理来自多个应用程序的请求并将它们绘制在同一表面上,因此将其分为不同的过程。
- 网络进程(NetWork Process),负责页面的网络资源加载,之前是放在浏览器进程中的一个线程运行,现在独立出来。
-
当软件在计算机上的目标操作系统上运行时,它需要访问计算机RAM(随机存取存储器):
- 加载自己需要执行的字节码
- 存储被执行的程序使用的数据值和数据结构
- 加载程序执行所需的任何运行时系统
当软件程序使用内存时,除了用于加载字节码的空间外,它们还使用两个内存区域,堆栈和堆内存
Stack
- 静态内存分配,后进先出 ( LIFO ).
- 多线程应用程序的每个线程可以有一个堆栈。
- 堆栈的内存管理由操作系统完成。
- 存储在堆栈上的典型数据是局部变量(值类型或原语、原语常量)、指针和函数帧。
Heap
- 堆用于动态内存分配,与堆栈不同,程序需要使用指针在堆中查找数据。
- 储存具有动态大小的数据。
- 堆在程序的线程之间共享。
- 存储在堆上的典型数据是全局变量、引用类型(如对象、字符串、映射和其他复杂数据结构)。
JAVA和C++的区别(GC)
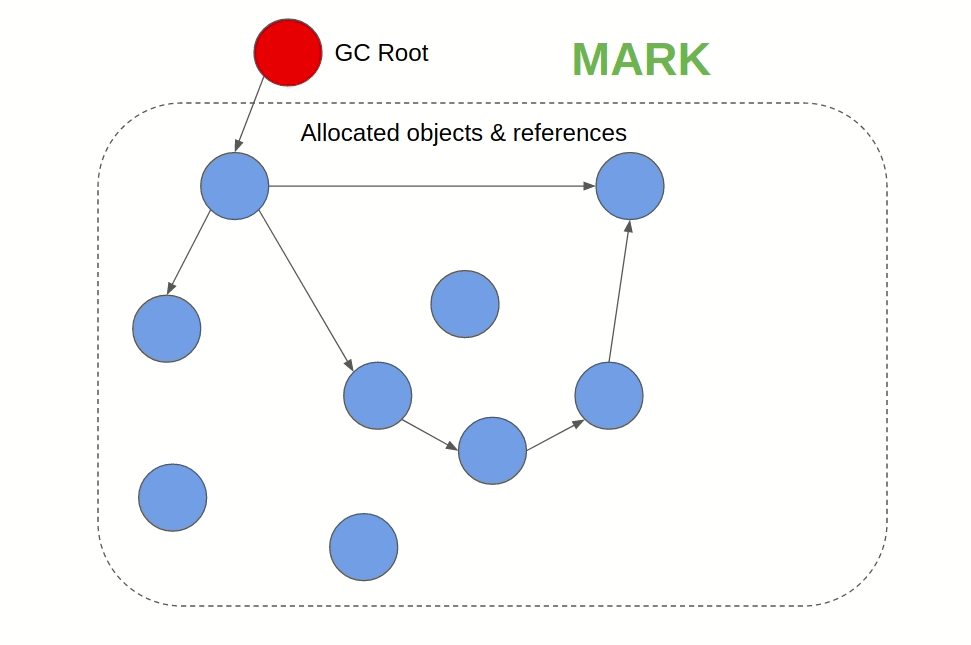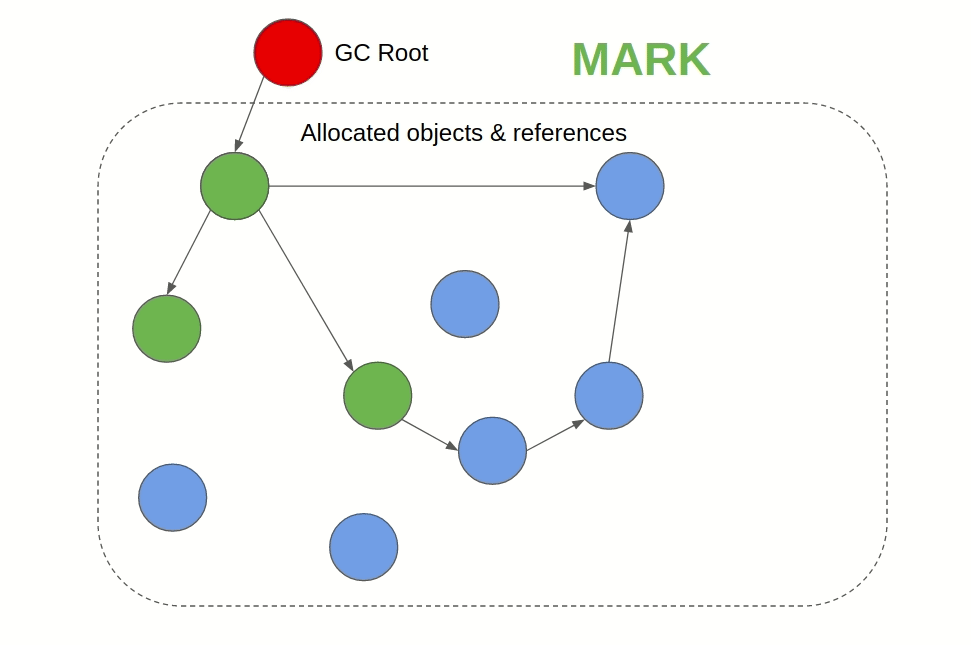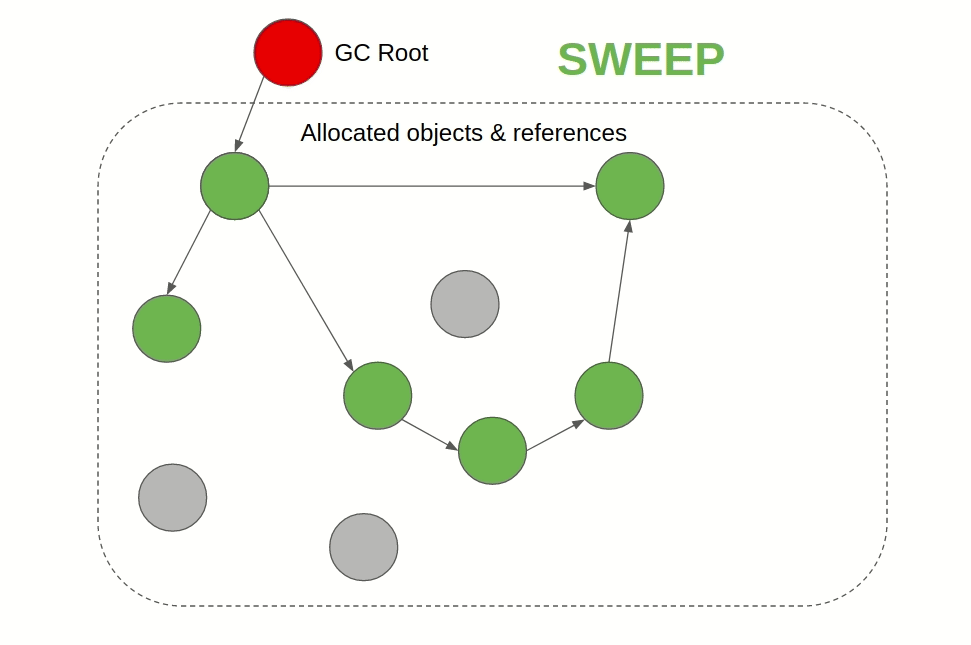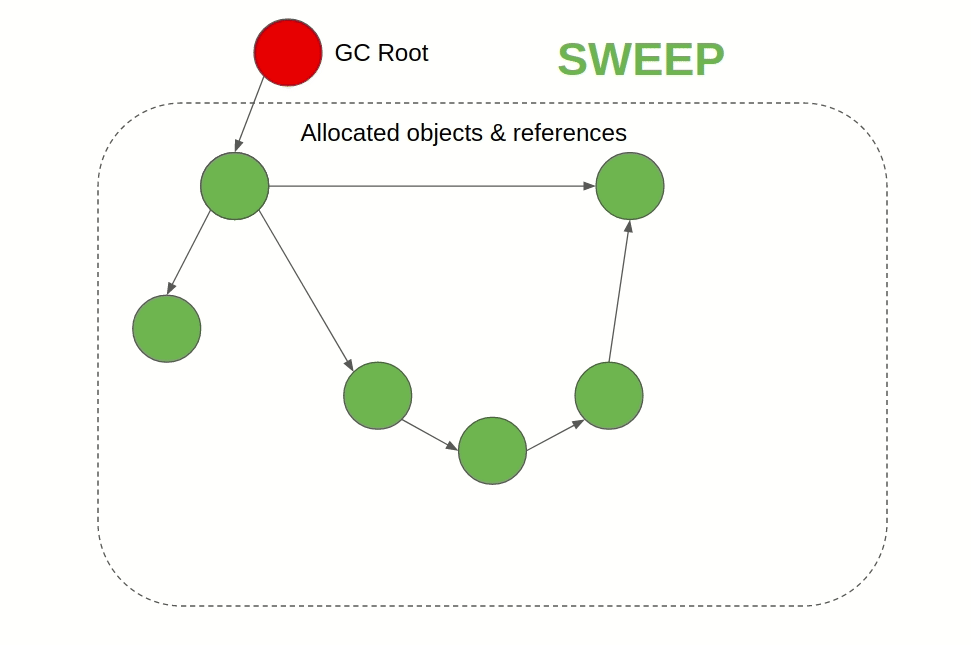
Mark & Sweep GC(JVM(Java/Scala/Groovy/Kotlin)、JavaScript)
遍历所有的被引用的对象,并标记。清理所有的未被标记的对象
引用计数GC(c++)
在这种方法中,每个对象都会获得一个引用计数,该计数会随着对其引用的更改而递增或递减,并且当计数变为零时完成垃圾收集。
- 无法处理循环引用
-
主存储器(Main Memory)
主存储器是计算机运行的核心,是CPU和 I/O 设备共享的快速存储库,也称为RAM。
是易失性内存,断电时数据回丢失
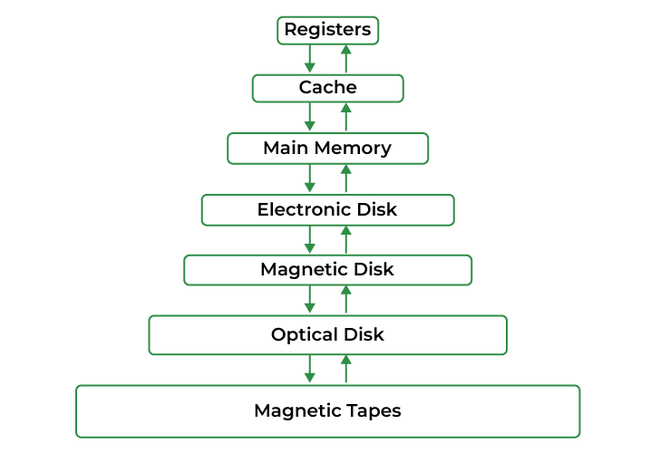
内存管理
在不同进程之间细分内存的任务称为内存管理,用于管理进程执行期间主存和磁盘之间的操作,主要目的时实现内存的高效利用
- 在进程执行之前和之后分配和取消分配内存。
- 跟踪进程使用的内存空间。
- 尽量减少碎片问题。
- 正确使用主存。
- 在执行流程时保持数据完整性。
逻辑地址和物理地址
- 逻辑地址:虚拟地址,由cpu生成。可以定义进程的大小,更改逻辑地址
- 物理地址:真实地址,由MMU计算.
静态加载和动态加载
将进程加载到主内存中是由加载程序完成的。
- 静态加载:将整个程序加载到固定地址,需要较多的内存空间
- 动态加载:在动态加载中,例程在调用之前不会加载。所有例程都以可重定位加载格式驻留在磁盘上。动态加载的优点之一是永远不会加载未使用的例程。
静态链接和动态链接
要执行链接任务,需要使用链接器。链接器是一种程序,它接受一个或多个由编译器生成的目标文件,并将它们组合成一个单一的可执行文件。
- 静态链接:在静态链接中,链接器将所有必需的程序模块组合成单个可执行程序。所以没有运行时依赖。
- 动态链接:在动态链接中,每个适当的库例程引用都包含“存根”。存根是一小段代码。执行存根时,它会检查所需的例程是否已在内存中。如果不可用,则程序将例程加载到内存中。
分页
-
进程生命周期
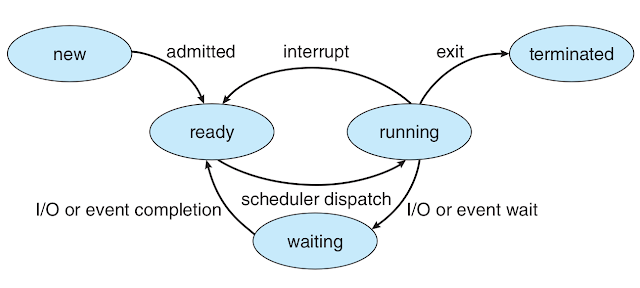
- new:进程首次启动/创建时的初始状态。
- ready:进程在就绪队列中等待分配给处理器。
- running:一旦被分配给处理器,就改为运行态。
- terminated:完成或遇到错误,进入终止状态。等待从主存中删除。
计网
流媒体传输协议
传输层协议:
TCP:面向连接的、可靠的、基于字节流的
SYN:同步序列号;ACK:确认字符;seq:序列号
三次握手:
- Client => Server : SYN = 1, seq = x
- Server => Client : SYN = 1, ACK = 1, seq = y, ack = x + 1
- Client => Server : ACK = 1, seq = x + 1, ack = y + 1
四次挥手:
- Client => Server : FIN = 1, seq = x
- Server => Cilent : ACK = 1, seq = y, ack = x + 1
- Server => Client : FIN = 1, ACK = 1, seq = z, ack = x + 1;服务端关闭
- Client => Server : ACK = 1, seq = x + 1, ack = z + 1
- 等待两倍报文最大生存时间后客户端关闭
UDP:无连接的、不可靠的、面向数据报的
区别:
- TCP是一对一的传输,UDP支持一对一、一对多、多对多的交互通信
- TCP首部长度长,开销较大;UDP首部8个字节,固定不变,开销较小
Socket通信:
流程:服务端监听,客户端请求,确认连接进行通信
c++下的Socket
创建Socket
1
2
3
4
5
6
7/*
af:一个地址家族,通常为AF_INET
type:套接字类型,SOCK_STREAM表示创建面向流连接的套接字;为SOCK_DGRAM,表示创建面向无连接的数据包套接字;为SOCK_RAW,表示创建原始套接字.
protocol:套接字所用协议,不指定可以设置为0
返回值就是一个socket
*/
SOCKET socket(int af, int ytpe, int protocol);绑定端口和地址
1
2
3
4
5
6
7
8
9/*
sockeSrv为socket;addrSrv为结构体指针,包含端口和IP地址信息;第三个参数为缓冲区长度,一般为sizeof计算
*/
SOCKADDR_IN addrSrv;
addrSrv.sin_family = AF_INET;
addrSrv.sin_port = htons(8088); //1024~65535中的端口号
addrSrv.sin_addr.S_addr = inet_addr("154.152.70.22");
//通过inet_addr函数将字符串转化为整型(in_addr_t)
bind(sockSrv, (LPSOCKADDR)&addrSrv, sizeof(SOCKADDR_IN));服务端监听
1
2
3
4
5/*
1:socket
2:等待连接队列长度
*/
listen(sockSrv, 10);服务端接收客户端请求
1
2
3
4
5
6
7/*
1:socekt
2:包含客户端端口IP信息的sockaddr_in结构体指针
3:接收参数addr的长度
返回值为socket。可以在客户端和服务端接受和发送数据
*/
accept(sockSrv, (SOCKADDR*)&addrClient, sizeof(SOCKADDR));关闭连接
1
int colsesocket(SOCKET s)
客户端发送连接请求
1
2
3
4
5
6/*
1:socket
2:结构体执政,包括主机的IP地址
3:缓冲区大小
*/
connect(sockCLient, (SOCKADDR*)&addrSrv, sizeof(addrSrv));接收消息
1
2
3
4
5/*
1: 建立好连接的socket
*/
char buff[1024];
recv(sockClient, buff, sizeof(buf), 0);发送消息
1
send(sockClient, buff, sizeof(buf), 0)
通信
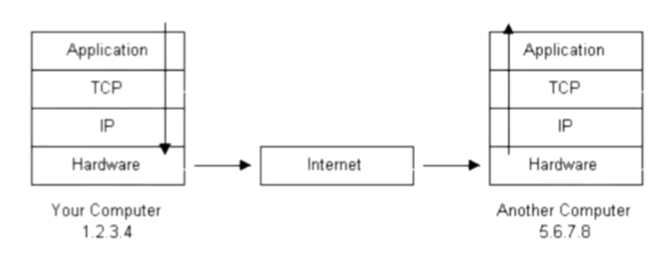
Application 层
- 对数据进行编码
- 发送者信息
TCP 层
- 全双工通信(可以接收和发送)、可靠的(确认和重传、数据校验、分片和排序)、stream流的、协议(protocal)
stream 流 :即连续的,有前后、有顺序的。在任意指定时刻,可读的数据量都是不确定的
- 如何优化包传输/即包大小
packet 包:不连续的,以包为发送单位。
IP 层
- 对端的身份的定位
Domain Name Service DNS:域名解析服务
- 将网址翻译成一个能够在互联网上找到相应的服务器的IP地址。
-
select
单线程模型,阻塞操作
只能同时处理一个client的连接,没有处理多个连接的能力
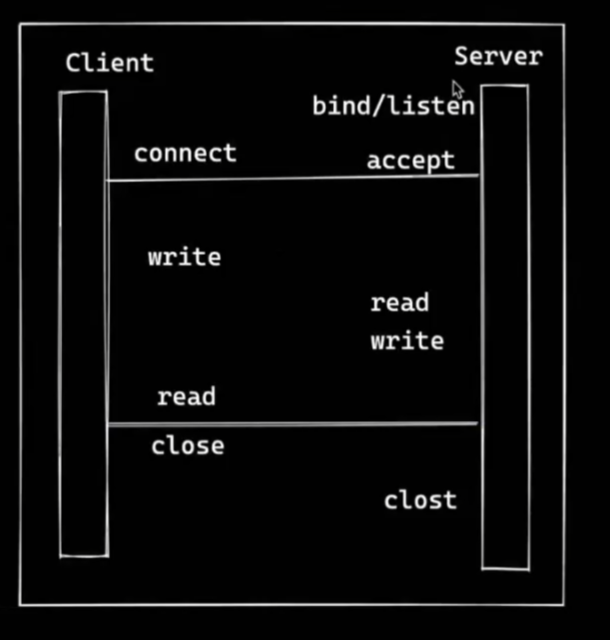
多线程模型
- 每个client对应一个线程连接
- 管理线程过多,效率过低
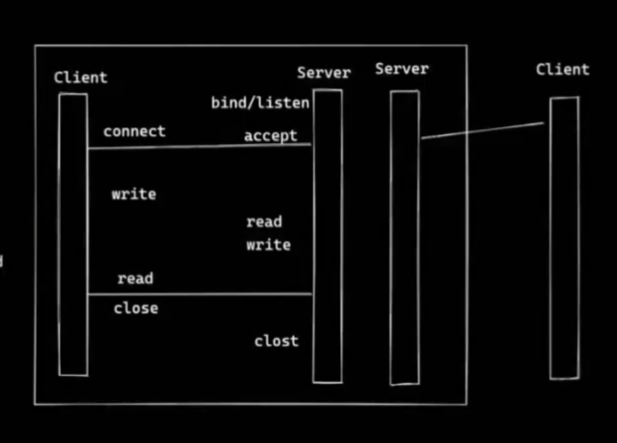
多路复用模型(epoll)
- 一个线程可以对应多个连接
- 相当于线程池
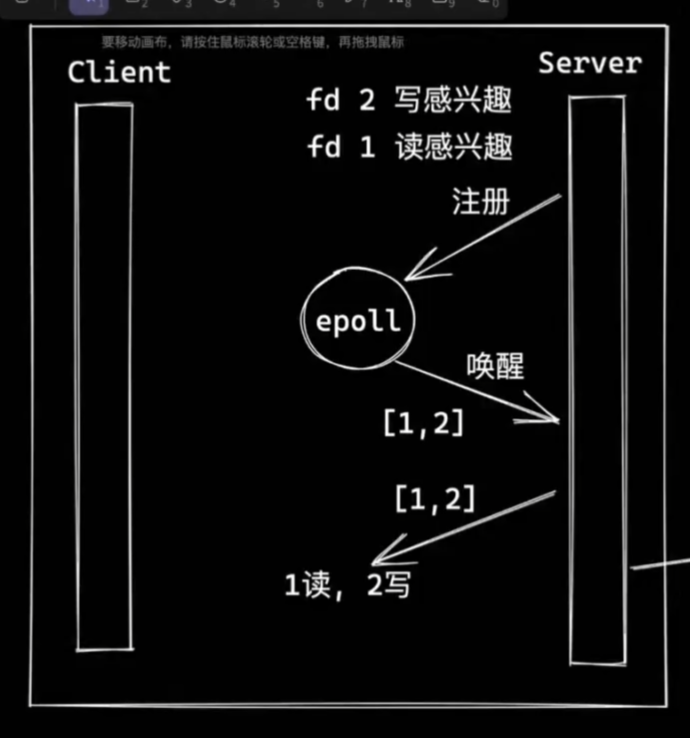
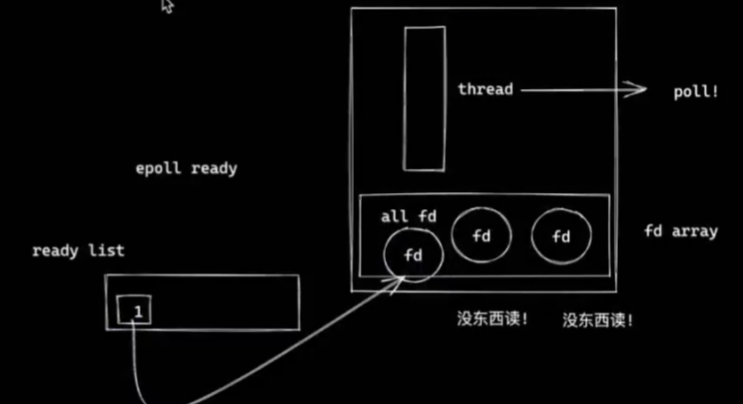
一个线程处理多个连接(epoll)
- ready list 保存所有的就绪fd的指针
- 每次挂起操作只会从ready list中查找就绪的fd
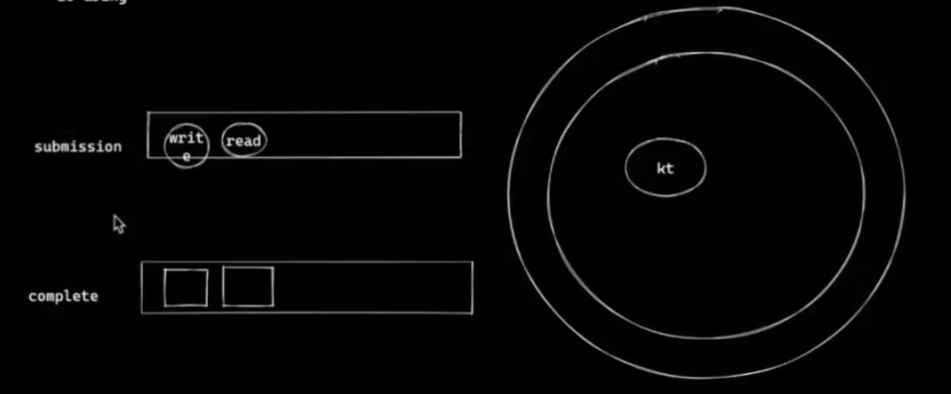
io uring
- submission:提交的请求操作列表
- complete:请求操作的返回结果
- 用户态可访问的无锁环形队列
HTTP:超文本传输协议
-
HTTP/0.9
- 只有 GET
- 没有标题/响应的必须是HTML
HTTP/1.0
增加了HOST
可以处理其他格式的响应(图像、视频等)
添加了跟多的方法(POST、HEAD)
添加了状态码以识别响应
响应格式
1
2
3
4
5
6
7
8
9200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
(response body)
(connection closed)不能有多个请求,对于任意的下一个请求,都需要新建一个连接
HTTP/1.1
- 添加了新的方法(PUT、PATCH、OPTIONS、DELETE)
- 持久连接:一个链接可以处理多个请求
- 引入了对流水线(pipelining)的支持,即客户端可以发送多个请求,不需要等待服务器的响应,而服务器必须按接收顺序发送响应
HTTP/2
- 二进制 替换 文本
- 多路复用:通过单个连接处理多个http请求
- 使用HPACK进行header压缩:文字值使用霍夫曼代码编码,标头表由客户端和服务器以及客户端和服务器维护在后续请求中省略任何重复的标头。
- Server Push :单个请求可以有多个响应
- 请求优先级
- 安全
状态代码
- 1xx 信息性
- 2xx 成功
- 3xx Redirection
- 4xx 客户端错误
- 5xx 服务器错误
-
编译原理
数据对齐
1.数据或结构体、类中的数据成员的存储起始地址为有效对齐值N的倍数。
2.结构体或类或联合体最终的大小应为有效对齐值N的倍数(圆整)。
基本数据类型
char: 1;short:2;int:4;float:4;long:4;long long:8;double:8;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Cl{
char a;
int aa;
short aaa;
}
//sizeof(Cl) = 12
class C2{
char a;
short aa;
int aaa;
}
//sizeof(c2) = 8
class C3{
char a;
short aa;
double aaa;
}
//sizeof(c3) = 16;
class C4{
char a;
double aa;
short aaa;
}
//sizeof(c4) = 24;
数据库
关系型数据库:
优点:
- 结构简单、易于维护:都是使用表结构,格式一致;数据库设计和规范化过程也简单易行和易于理解。
- 使用方便、灵活:使用标准查询语言SQL,允许用户几乎毫无差别地从一个产品到另一个产品存取信息。与关系数据库接口的应用软件具有相似的程序访问机制,提供大量标准的数据存取方法。
- 复杂操作:可以进行join等复杂查询;
- 保持数据的一致性;
- 由于以标准为前提,数据更新的开销小(相同的字段基本都是只有一处);
- 存在很多实际成果和专业技术信息(成熟的技术)。
缺点:
- 数据类型表达能力差:关系数据模型不直接支持复杂的数据类型。
- 复杂读写功能差。
- 支持长事务能力差:由于RDBMS记录锁机制的颗粒度限制,对于支持多种记录类型的大段数据的登记和查询来说,简单的记录级的锁机制是不够
- 环境应变能力差:在要求系统频繁改变的环境下,关系系统的成本高且修改困难。
- 读写性能:面对海量数据的高并发读写需求,效率就会变得很差,硬盘I/O是一个很大的瓶颈;
- 扩展方式:固定的表结构,灵活度稍欠,如字段不固定时的应用;
存储过程:
优点:
1、重复使用:存储过程可以重复使用,从而可以减少数据库开发人员的工作量。
2、减少网络流量:存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数就可以了,因此降低了网络传输的数据量。
3、安全性:参数化的存储过程可以防止SQL注入式攻击,而且可以将Grant、Deny以及Revoke权限应用于存储过程。
缺点:
1、更改比较繁琐:如果更改范围大到需要对输入存储过程的参数进行更改,或者要更改由其返回的数据,则仍需要更新程序集中的代码以添加参数、更新 GetValue() 调用。
2、可移植性差:由于存储过程将应用程序绑定到 SQL Server,因此使用存储过程封装业务逻辑将限制应用程序的可移植性。如果应用程序的可移植性在您的环境中非常重要,则需要将业务逻辑封装在不特定于 RDBMS 的中间层中。
-
要求
可靠性(Reliability)
系统在 困境(adversity,比如硬件故障、软件故障、人为错误)中仍可正常工作(正确完成功能,并能达到期望的性能水准)。
可伸缩性(Scalability)
有合理的办法应对系统的增长(数据量、流量、复杂性)。
可维护性(Maintainability)
许多不同的人(工程师、运维)在不同的生命周期,都能高效地在系统上工作(使系统保持现有行为,并适应新的应用场景)。
设计模式
图形学(大概)
mipmap:多级渐远纹理
一系列的纹理图像,后一个纹理图像是前一个的二分之一。
当物体距观察者的距离超过一定的阈值,OpenGL会使用不同的多级渐远纹理,即最适合物体的距离的那个纹理。